
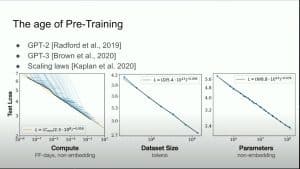
Na recente conferência Neural Information Processing Systems (NeurIPS) em Vancouver, Ilya Sutskever, o cofundador da OpenAI, apresentou uma palestra instigante na qual argumentou que a era do pré-treinamento de inteligência artificial está se aproximando do fim. Essa afirmação ambiciosa tem um efeito sério no futuro da IA, com Sutskever prevendo o advento da superinteligência da IA.
As palestras de Sutskever abordaram o crescimento exponencial em tecnologias de IA, incluindo a crescente capacidade de hardware de computação, software e algoritmos de aprendizado de máquina. De acordo com o cofundador da OpenAI, o advento de recursos computacionais poderosos está começando a superar os requisitos de dados para treinar modelos de IA. Ele fez uma analogia interessante, comparando dados a combustíveis fósseis que são limitados e podem acabar. Em seu discurso, Sutskever disse:
“Os dados não estão se expandindo porque tínhamos apenas uma internet. Poderíamos até dizer que os dados são o combustível fóssil da IA. Ela foi criada de alguma forma, e agora a usamos, e atingimos o pico de dados, e não teremos mais que lidar com os dados que temos.”
Esta previsão indica uma mudança significativa na evolução da IA. Sutskever enfatizou que, com os dados se tornando um fator limitante, os avanços futuros na inteligência artificial se concentrarão em evoluir além da dependência tradicional de vastos conjuntos de dados. Ele acredita que a IA agêntica, os dados sintéticos e a computação baseada em inferência serão os principais fatores a moldar a próxima fase do desenvolvimento da inteligência artificial.
Uma das perspectivas mais empolgantes que Sutskever destacou foi o aumento potencial da IA agêntica. Em contraste com os algoritmos de IA disponíveis, que são principalmente passivos e exigem atividades mediadas por humanos para sua execução, a IA agêntica seria capaz de agir de forma autônoma sem controle humano. Essa evolução pode mudar a IA de uma ferramenta que os humanos sujeitam ao seu controle para uma entidade mais autônoma capaz de interação complexa com o mundo.
A ideia de IA agêntica já chamou a atenção das indústrias de criptomoedas e blockchain, onde modelos de grandes linguagens (LLMs) e moedas-meme de IA estão decolando. Um exemplo notável é o Truth Terminal, um LLM de IA viral que promoveu o token Goatseus Maximus (GOAT), que atingiu uma capitalização de mercado de US$1 bilhão. O interesse significativo neste esforço baseado em IA chamou a atenção para a capacidade emergente de agentes de IA para impactar mercados e comportamentos, reforçando assim a noção de que a IA ocupará o centro do palco em futuros sistemas econômicos e sociais.
Alucinações de IA ocorrem quando modelos geram saídas com base em dados incorretos ou incompletos, um fenômeno frequentemente causado pelo uso de conjuntos de treinamento desatualizados ou imprecisos. Como o processo de pré-treinamento de IA desempenha um papel cada vez maior em LLMs mais antigos, esses sistemas mostram uma tendência a diminuir seu desempenho de acordo com sua sensibilidade a menos informações, o que resulta em resultados menos confiáveis e frequentemente incorretos. A possibilidade de que a IA agêntica, capaz de raciocínio autônomo e melhor tomada de decisão, possa ajudar a resolver esse problema pode levar a sistemas de IA mais confiáveis e eficientes.
Um aspecto central da palestra de Sutskever, no entanto, foi a possível contribuição de dados sintéticos para o futuro da IA. Com os dados se tornando cada vez mais escassos, dados sintéticos, criados artificialmente sem nenhuma relação empírica com o mundo real, podem oferecer uma alternativa razoável. Dados sintéticos podem ser ajustados às condições necessárias, permitindo o treinamento de modelos de IA, sem as limitações associadas ao uso de big data que podem não estar mais disponíveis.
Esse avanço pode ser particularmente valioso em domínios como assistência médica, onde as limitações de privacidade e dados frequentemente impedem o desenvolvimento de modelos de IA fortes. Potencialmente, essas limitações podem ser contornadas usando dados sintéticos, permitindo que seus desenvolvedores de IA criem modelos mais flexíveis e escaláveis sem exigir grandes quantidades de dados do mundo real.
Sutskever também abordou a crescente relevância da computação de tempo de inferência para a IA. A inferência é o processo pelo qual um modelo de IA já treinado prevê ou decide sobre novos dados de entrada. À medida que esses sistemas de IA se tornam cada vez mais complexos, a eficiência da inferência — a velocidade e a precisão com que um modelo de IA pode executar uma nova entrada — também deve ser considerada cada vez mais importante.
Na evolução da IA, uma tendência surgirá com a otimização do tempo de inferência, permitindo que os modelos de IA sejam mais eficientes e tomem decisões em tempo real. Isso será especialmente importante para aplicações como direção autônoma, controle remoto de dispositivos ou gerenciamento de propriedades, onde a velocidade e precisão são essenciais para o sucesso.
A visão de Ilya Sutskever sobre o futuro da IA, no entanto, é uma mudança de paradigma em relação ao uso limitado de grandes quantidades de dados e ao pré-processamento com pré-treinamento. Com o progresso contínuo em hardware, software e algoritmos de IA, o campo provavelmente experimentará uma mudança em direção a sistemas de IA mais autônomos e agentes, capazes de pensamento, raciocínio e ação independentes. A criação de dados sintéticos e os avanços na computação de tempo de inferência desempenharão um papel crucial na superação das limitações dos modelos de IA atuais e que a IA retome a evolução em direção à superinteligência.
